

Estimating the Pose of a Medical Manikin
In the ViTAWiN research project, a medical manikin was to be integrated into the VR training. The goal was to haptically augment the virtual patient by displaying it with the position, orientation and body pose corresponding to the real manikin, allowing users to haptically interact, i.e. touch, the virtual patient. The medical manikin thus serves as a haptic proxy for the virtual patient.
We explored various approaches of determining the manikin's position, orientation and body pose, and finally chose to use OpenPose, a Deep Learning-based optical body keypoint detector, to process images of the manikin taken by the HMD's integrated stereo camera.
For the full details on our approach, please see our Open Access paper: "Estimating the Pose of a Medical Manikin for Haptic Augmentation of a Virtual Patient in Mixed Reality Training".
Pose Estimation Using Body Keypoint Detection
Pose estimation is the task of finding the rotation angles of all the mechanical joints that connect the various limbs of the medical manikin. Typically, a manikin has far fewer joints than a real human body.
A body keypoint is a "landmark" on the human body, such as nose, eyes, ears, elbows, shoulders, knees, ankles, etc. The detection of such points in camera images of people has become a standard task for many applications. With the advent of Deep Learning, keypoint detection quality and performance has been greatly improved using Convolutional Neural Networks (CNNs).
In ViTAWiN, we build on body keypoint detection to estimate the pose of the medical manikin. We capture the manikin using the cameras built into our HMD (Valve Index) from different perspectives and employ OpenPose, an open source body keypoint detector that uses GPU computing, to locate the keypoints of the manikin in the camera images. Since manikins are modeled after humans, standard body keypoint detectors can be applied without the need for specialized training.
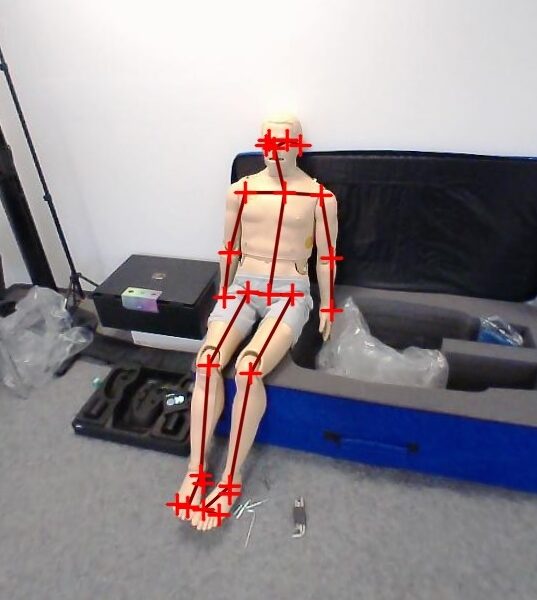
Keypoint detection alone does not provide any 3D information, which we need for our Virtual Reality application. Therefore, we take images from multiple perspectives, and make use of the fact that the cameras are mounted to the HMD, which is tracked by the SteamVR tracking system. After performing some calibration steps, we then know where the camera was located when each image was taken. This, in turn, allows us to employ triangulation and compute 3D keypoint coordinates from multiple 2D observations.
The 3D keypoint data is then used to obtain an initial estimate of the manikin's position and orientation. The final step is a non-linear optimization that takes into account all observed keypoints and tries to rotate the virtual patient's limbs in such a way that its keypoints line up with the keypoints of the manikin.

In a simple evaluation we measured an average accuracy of 4 cm, which refers to the distance between various points on the manikin and the same points on the virtual patient. While this needs to be improved in order to be applicable for precise haptic tasks, we believe it to be sufficient for simple social interactions, such as touching the patient's shoulder to give comfort.